NoSQL + SQL = MySQL 8; Keynote OSI2019
Slides from the keynote presented at Open Source India 2019 at Nimhans convention center Bangalore. As usual lots of interesting folks. Lots of focus on Open Source.
Met people from the SODA foundation who are trying to standardize the IO layer across all cloud implementations. All the best guys.
Also met folks from MOSIP who have an effort ongoing to help countries create their own UID. Seems like they already have some traction.
Also met an interesting person trying to think about Indian design and creativity in software. After Chumbak it does make sense to think about how not only UI but the software development process needs more creativity.
Thank you EFY for the opportunity. Great job and all the best for the future.

MySQL 8 loves Javascript @jsfoo
Presented at the JSFoo conference for the first time.
The slides are uploaded here https://www.slideshare.net/SanjayManwani/mysql-8-loves-javascript via @SlideShare
Quick impression on the conference:
1. Very buzzy you could see the high energy levels. Lots to learn about javascript and the speakers were also enthusiastic to speak. 700 attendees.
2. The focus was spot on. Security is something that everyone is worried about.
3. Staff was always on the spot and helpful. The organization looked great with the big video boards announcing the next talk etc.
4. It was also informal communication between the speakers with there being a whatsapp group for speaker to interact with one another.
5. A few things that I did point out to organizers e.g. the banners on the road outside were not there (disallowed because of a government conference that was happening in parallel), more aspirational attendees etc.
All in all a big thanks to the has geek organizers, did enjoy the conference and would like to continue to be a part of the hasgeek conferences.
(Photo courtesy: official jsfoo photo tweeted by Zainab)
MySQL Whats New #gids16; slides
Had a wonderful session at the Great Indian Developer Summit 2016.
Thanks Saltmarch for a Great conference with wonderful attendance.
Lots of interest in MySQL document store. http://m.youtube.com/watch?v=1Dk517M-_7o
Slides are posted here: http://www.slideshare.net/SanjayManwani/mysql-whats-new-gids16
Also here is a picture of our booth.

MEB 4.0 allowing backup of MySQL 5.7 is GA
Announcing the availability of the newest version of MySQL Enterprise Backup (MEB) v4.0.0, the online MySQL backup tool.
You can now download it from the My Oracle Support (MOS) website as the latest GA release. This release will be available on eDelivery (OSDC) after the next upload cycle.
MySQL Enterprise Backup (MEB) is a commercial extension to the MySQL family of products.
Please do note that MySQL Enterprise Backup v4.0.0. backs up only MySQL server 5.7.
For all previous versions of server i.e. 5.5 and 5.6 please continue to use the MySQL Enterprise Backup 3.12 series.
MEB 4.0. ensures that the Server 5.7 enhancements like the new 32 and 64 K page sizes and general table spaces can also be backed up.
There was a long standing request to store the Tape ID when backing up using the SBT interface. This request is finally supported using MEB 4.0.
Documentation is available at http://dev.mysql.com/doc/mysql-enterprise-backup/4.0/en/
Do let us know your feedback.
MySQL User Camp @ Bangalore on 26th June
MySQL India team is back with another MySQL user camp.
The day of the week, time and venue remains the same:
Date: Jun 26th, 2015
Day : Friday
Time: 3-5:30 pm
Place: OC001, Block1, B wing, Kalyani Magnum Infotech Park, J.P Nagar, 7th Phase Bangalore, India
During our previous meetings we were requested by our attendees that they would like to hear about implementation of GTID by the MySQL community. We have listened to you and requested a community member to talk about their experience with the implementation of GTID. Our first talk is :
- MySQL Tools Usage in Rakuten and Overview of Replication GTIDs
There is also a lot of interest in our new delivery vehicles for MySQL packages. Using the new YUM repos you can stay up to date with the latest MySQL releases. You need not wait for your distro to update MySQL in their release packages. The release team which is responsible for this repo magic will update you about how this happens in our second talk :
- MySQL Software Repositories
More information for the free registration can be found at:
- Facebook Group: MySQL User Camp
- Google Group: bangalore-mysql-user-camp
- Linked-in Group: MySQL India
Look forward to see you there.
How to crack that “software product company” campus interview
During my many years of recruiting at engineering colleges, I have sometimes wondered why the simple code to crack the campus interview has not been figured out by students.
At the end of the interviews conducted by our company, the conversation with the campus hiring professor goes along predictable lines. We talk about how the students could have done better.
This blog is about my advise to ace the campus interview.
Surprisingly the structure of the interviews has remained the same since the last many years that I have been recruiting.
What most product companies are looking for, is exactly the same things:
1. Do you have basic intelligence to think and give a solution
2. Can you think programmatically
3. How well do you know your data structures
4. Do you understand operating systems
5. Do you have some idea about distributed programming
6. Do you have some idea about the product/company for which you are being recruited
The reason that the first 3 and last 3 have a gap in between is because the first 3 are must haves, while the last 3 are good to have. An average company not looking for top notch programmers will recruit you even if you are good with the first 3.
The best companies will look for all the 6.
It is not very difficult to prepare for the above. Lets go over each :
1. Do you have basic intelligence to think and give a solution
Remember, you have made it to a the computer science department of a good college selected by this company for campus hiring. You also have good grades to have made it to the cut off list.
As long as you remember that and don’t get either too tense or over confident; thinking should not be a problem.
Also remember the recruiters want to hire you, they will try to give hints about the solution.
Listen to them carefully and even if you cannot get to the final solution, you will definitely be able to make the recruiters understand that you can think along the correct lines.
Don’t bullshit and don’t try to hide behind jargon. These are experienced engineers who have come for recruitment, they will see through these tricks. If you are not getting it, saying so and asking for a different problem will probably be seen as a more sincere answer.
Looking at a few problem solving questions on the internet may also not be a bad idea.
2. Can you think programmatically
If you don’t want to program, you are of no use to a product company. Whether it is development, quality, sustaining or even release engineering, you need to love programming. You have spent 4 years studying computer engineering, and will need to program for atleast the next 7 years if not more. Even beyond that you need to understand programming and to be able to think programmatically.
Given any problem, you should be able to write an algorithm to solve it. Preferably it should be in a real computer language. You don’t need to know all the tricks and tips of C++ or Python but you need to be thorough with you basic programming.
Most product companies; if they are working in a core technology, are happy if you know C. C is the most used programming language for core infrastructure. If you can master C then any other language should not be a problem.
So here comes my first recommendation about which book to read :
The C Programming Language (Ansi C Version) Paperback – 1990
by Brian W. Kernighan (Author), Dennis M. Ritchie (Author)
It is not only the oldest book on C but the most crisp and concise. Read the book and solve the problems.
Once you are thru this book the second hurdle should not be a problem.
3. How well you know your data structures
What hammer, drill and other tools are to a carpenter, data structures are to the computer programmer. You need to know what data structure you need to use to solve a problem. All problems are not nails and arrays are not the hammer. There are more elegant solutions. Running scared of pointers and trees will not get you too far.
If you have read the C Programming book and solved the problems, you should be good with the basic data structures.
Having said “right data structure for the right job”; the recruiters will try and ask you to use pointers to solve a problem that can easily be solved by arrays. Be ready for that. Know the memory constraints and the order of the algorithm for which you are using your data structure.
There are many books on algorithms and data structures. Any one should be good, but being an old man I still have my faith in:
The Art of Computer Programming: Fundamental Algorithms v. 1 Paperback – 1 Dec 2008
by Donald E. Knuth (Author)
You don’t need to learn the whole book, if you can just be thorough with lists, trees and a bit of recursion from this book along with searching and sorting, that should be good enough.
There is now some new thinking about programming in terms of design patterns. Knowing design patterns is also great.
You do need to go atleast 1 step beyond the MVC though. The plain MVC is the one pattern everyone resorts to and no malice towards the good old MVC but frankly after the 5th college grad mentions MVC, it gets too boring.
That covers the must haves. With the above, you should have your step in the door and probably an easy shot at any service company.
But if you need to get into a specialized R&D type product company there is a bit more.
4. Do you understand operating systems
Who cares about the old operating system? The Internet runs on scripting languages.
Wrong and Wrong.
Whether your programs are running on the web or on the cloud, ultimately your program ends up on or interacts with a server that runs an operating system.
You are lucky that all operating systems whether by Apple or Microsoft or IBM are now converging towards the Linux type of operating system. So it is a simple choice, which OS internals you need to learn about.
You need to know the basic old Unix.
This was the operating system which was a trendsetter for the filesystem, the process structure and other OS primitives that you see in most modern operating systems. That brings me to my 3rd book recommendation.
The Design of the Unix Operating System Paperback – 1988
by Bach Maurice J. (Author)
I know that recommending a book from 1988 is not sexy, but I have not found a more simple and elegant explanation of the building blocks of the operating system than this book. Try it, it does read like a novel and has excellent diagrams to explain the basic OS structures. Also since it is not cluttered will all the new extensions to the OS, the basics can be grasped as they were designed.
Otherwise any good book on OS should be good enough.
You need to be really thorough when you go for the interview, the purist programmers who are trying to recruit you want to know exactly what happens to a program, how it compiles and how it gets executed on that OS. You need to be prepared with how the program is structured after compilation and exactly how the OS goes about executing it.
5. Do you have some idea about distributed programming
We talked about the good fortune that all the operating systems are trending in the same direction. Unfortunately there is another trend which makes the life of programmers difficult. That trend is distributed programming.
Earlier there was a single CPU and single threaded programs, now there are multiple cores on a single chip and multiple threads executing in parallel. There are now also clusters of servers and clouds of internet. Your program has to ensure that it can be broken into multiple threads and multiple servers elegantly and that it recombines to generate the final result well.
This opens a whole can of worms for synchronizing threads and programming well, so that no memory corruption takes place.
Debugging such multi threaded programs is a nightmare even for veteran programmers. Most of the last minute issues for a product release are related to bad timing in the synchronization of multiple threads. To make matters worse, some of the problems are difficult to reproduce since they occur intermittently.
The red eyes of your recruiter may indicate that s/he probably has just come back after fight with a naughty distributed program. When they ask you about threads, processes, synchronization, locking; you need to answer in a coherent way. You do not want to be the target of their pent up anger against the last locking/synchronization issue whose resolution kept them awake a few nights.
You are best prepared if there is atleast one multi threaded client server program you have written and ensured that 10 – 20 parallel sessions on the program do not crash the server.
If you have written the program above; it should be good enough, but if you need a book recommendation for writing that client server program and want to make you life interesting with some socket programming, here goes :
Unix Network Programming: The Sockets Networking Api – Volume 1 Paperback – 2005
by Stevens W. Richard (Author), Fenner Bill (Author), Rudoff M. Andrew (Author)
While we are on distributed programming, one of the concepts that is kind of linked to it, is the issue of security.
Many clients accessing servers remotely need to have a security infrastructure. Some knowledge of security, for example: What PKI really means; is always good.
6. Do you have any idea about the product/company for which you are being recruited
Finally; yes finally, if you have reached till here in the interview, your recruiters should be smiling.
But they still want to know your interest in the job you are being recruited for.
So a basic search on the internet can be done even while you are waiting for the interview.
If you are really serious then you would know atleast some details about the company
i.e. who founded it, why it is successful etc.
Most product companies are working on cutting edge technologies.
For example with MySQL you need to know your databases.
What is a transaction? What is this whole buzz about SQL and NOSQL ?
Issues with multi tenancy for the internet ? What is multi master replication ? etc.
Similarly for the company you are aiming at, there must be technologies they care about.
Find out if there is a preso on slideshare about the implementation architecture of their software.
Also maybe google about the technologies that they use.
Reading a research paper related to the technology should be a feather in your cap. If you have read that research paper, make sure you mention it in your resume.
Remember; you have 3-4 years once you get into the college to prepare for 5 of the 6 points above.
Reading 2 books C & Unix and sections of the other books mentioned may mean a huge difference in your starting company and starting salary.
All the best; maybe we will see you around in our next campus interview.
Slides from the MySQL Session at Great Indian developer Summit 2015
Wanted to send a pointer to the slides from my session at #GIDS 2015.
Will followup with an impressions blog soon.
Impressions from OSI 2014
Time to do a quick blog about my impressions from OSI 2014.
It was a great conference, the organizers informed me that there were more than 2000 unique footfalls.
All the tutorial sessions on the first day were sold out. I saw people being turned back since there was simply no space in the rooms.
Our tutorial for MySQL was packed. Attendees remained till the end of the 3 hour long tutorial and Ronnen and Nitin had many engaging questions.
We found the audience to be a mix of open source professionals and some students. The Organizers were careful that the conference was not swamped by newbies.
Oracle’s keynote (slides) was well attended with more than 150 people. The audience listened intently and there were a lot of good questions during the questions slide. Though I had to limit the MySQL part to 25 minutes to allow Ramesh to talk about Oracle Linux, I hope that the highlights of MySQL were sufficiently conveyed. It was heartening to see nearly 90% of the hands going up when asked how many knew and had used MySQL.
There were 3 more MySQL sessions and all were well attended by people with real interest in the MySQL technology and probably ones who would go back and use the information from the talks.
The MySQL High availability with Replication New features (slides) was a very technical session with a deep dive into all that is new in replication. The Group replication part was a high level introduction into a topic that is still nearly a research topic. There were some very intelligent questions to understand how group replication worked, especially the conflict resolution; when multiple masters have conflicting updates.
The Mapping with MySQL (slides) was an introduction to GIS technology and its growing value for the current generation of web products. The terminology used in GIS was also discussed. GIS usage in MySQL was illustrated using an example use-case to find the nearest Thai restaurant close to an address. The presentation included the exact steps to solve this problem using MySQL.
Besides Oracle the other very visible presence was HP Helion with their newest cloud offerings. They attracted a lot of attention with their elaborate stall and many on the spot competitions with attractive prizes.
Wipro was also there to talk about their belief in the future of open source and a plan to have a 10,000 strong team to implement open source technologies for their customers.
I also attended a few MongoDB presentations. Though there is a lot of buzz around MongoDB, there did not seem to be too many actual users of MongoDB. Infact only 3 hands went up when the MongoDB architect asked the attendees how many had used MongoDB. IMHO, there are only a limited number of use-cases where MongoDB is a better fit v/s a relational database like MySQL. The 2 that I deduced from the presentations at OSI :
- Aggregating data from disparate data sources having no common schema
- Rapidly changing schema with historical data not requiring to be changed to fit the new schema
I would love to see real benchmarks with comparisons between MongoDB and relational databases.
There was also a lot of interest in presentations by entrepreneurs who had used open source software to give wings to their ideas. Though I could not attend the Justdial presentation, I did attend the Patterbuzz presentation. The energy and passion of Amit, the CEO of patterbuzz; was infectious. I was delighted to know that both these startups were using MySQL as the database of their choice. Would like to wish them the best so that they grow to a size where MySQL enterprise offerings have value for them.
Will sign off with a special thanks to the organizers, for a well-organized conference. The Oracle team and especially the MySQL engineers who made the effort to make our presence valuable at the conference also deserve a round of praise.
Hope to see you all at the next OSI conference.
Talking at Open Source India 2014
I will be talking at Open Source India scheduled at NIMHANS convention center at Bangalore on 7th and 8th of Nov 2014.
Oracle has been associated with the Open Source India conference for the past 4 years and this will be the 5th year when we will be taking part in this conference and talking about MySQL to the open source community.
OSI gives us a great opportunity and a platform to speak to and hear from the open source community. There have been some great interactions with developers, users, customers of MySQL and some really great people involved with the open source movement in India.
We look forward to interact with the open source community again. While we will likely learn much this conference about the progress of the open source community in India, we will also be informing you about the fantastic progress Oracle has made with MySQL in the past year. There are 5 sessions related to MySQL at OSI 2014
1. State of Penguin & Dolphin at 2.15 PM on 7th Nov.
It has indeed been a very exciting year for MySQL. I will be sharing the high level update for the exciting things happening at Oracle.
2. MySQL High Availability with Replication at 12.15 PM on 8th Nov
Oracle’s MySQL Engineers will talk about MySQL Fabric, which is a new sharding and HA solution for MySQL. Other new exciting replication features available for early access and feedback via labs.mysql.com include MySQL Group replication, which is the beginning of a Master-Master replication. We will also discuss new enhancements like multi-source replication, which allows you to aggregate the data from several servers for uses cases like backup or analytics.
3. Mapping with MySQL at 3.15 PM on 8th Nov
With the extensive usage of maps and graphical data, we want to provide native capabilities to consume and manipulate graphical data in next generation Web applications. This will be the session to inform you about the GIS capabilities built into the Development Milestone Releases of MySQL 5.7.
4. Improving Management Efficiency and Cloudscale of MySQL at 10.45 AM on 8th Nov
Our MySQL Cluster solution is now at the core of nearly all mobile provider networks for realtime delivery of mission critical data in order to make mobile connections possible. You will hear about the latest developments in the Development Milestone Release of MySQL Cluster 7.4, which now delivers geo-replication using asynchronous replication between MySQL Clusters.
5. MySQL Performance tuning at 10. 45 AM on 7th Nov 2014
If you want to get your hands dirty, hacking into MySQL, there is a workshop about tuning MySQL and all the metadata that is produced in the guts of the database as each query executes, or slows down or stalls. The dashboards and UI screens that simplify examining this metadata will also be explained.
This year we also share space at OSI with another Oracle open source product, namely Oracle Linux. I will leave the explanation of their sessions at OSI to the experts from that space in their own blogs.
Look forward to seeing you at OSI.
MySQL: The most popular open source database for WWW
(Note : This an Article from last year when MySQL5.6 was released)
While Database technology is one of the oldest branches of computer science, it remains a fundamental computer technology that continues to attract new research. The current focus of Databases technology is towards adapting hot new tends like multi-core chips, solid state devices, NOSQL and Cloud. So what does a contemporary internet developer look for in a database for the internet era? And why does MySQL remain the most popular database for the web?
For a database to be useful while developing products for the Web, the most important requirements are that it should be quick and easy to download, quick to set up, powerful enough to get the job done, be fast and flexible to use and finally be scalable on the newest hardware. Compatibility with the latest technologies like the cloud also remains foremost in the minds of developers since they need their products to be future proof.
You may notice, some of these requirements are common for any web product to be successful.
Let us go into the details of each of the above requirements, discuss their importance and look at how MySQL addresses them.
Quick set-up
In the instant web world of today with so many technologies competing for attention, you should either be available instantly on the cloud or should be quick and intuitive to be downloaded and setup. While 4-5 years ago someone may have given an application 10 minutes to download and set up, today, expect technologies to be ready for use within three minutes. The download process needs to be fast and the setup needs to be intuitive. A person using a technology for the first time does not want to be bothered with arcane questions to set up the software. The software should have reasonable defaults which can be tweaked later as the application is found suitable and is deemed worthy of some user time. It has been our endeavor to ensure that MySQL can indeed be set up, and the first query run within three minutes.
Many users and companies are looking to use the database as a service provided by a cloud provider. MySQL is the leading database in the cloud, offered by the vast majority of cloud services providers. Almost all cloud service providers like Amazon, Rackspace, Eucalyptus and Google provide MySQL as a service. It is a part of many cloud stacks including openstack and cloudstack which are available as a service. In many cases MySQL is the underlying database for cloud services provisioning and implementation. Being the ubiquitous cloud database means that MySQL is the best fit for the cloud and also the nimblest database to take keep up with the advances in cloud technology.
This assures a new user that MySQL is an easy database to use. It gives them the confidence that there will be a return for the time spent to adapt their software and infrastructure to the requirements for MySQL.
Basic features
When we talk about software being powerful there are many aspects that need to be covered.
The first requirement to be considered powerful is that all the basics must be well implemented. This creates a strong foundation on which this power is built. In terms of databases this means that all aspects of ACID (atomicity, consistency, isolation and durability) are implemented. ACID is provided in most databases by having strong transactional capabilities. This is usually achieved by implementing the 2 phase commit protocol. As an over-simplification we can say the transaction is done in two phases first it is written to a log file and then this log file is flushed to the disk.
This logging needs to happen at the lowest layer in a database called the Storage Layer.
Besides the logging, there are many crucial database level algorithms that need to be implemented in a balanced way to ensure that a Web database is able to shoulder the load that large websites expect to generate. A good transactional storage engine may need to implement its own threading, memory management and disk management
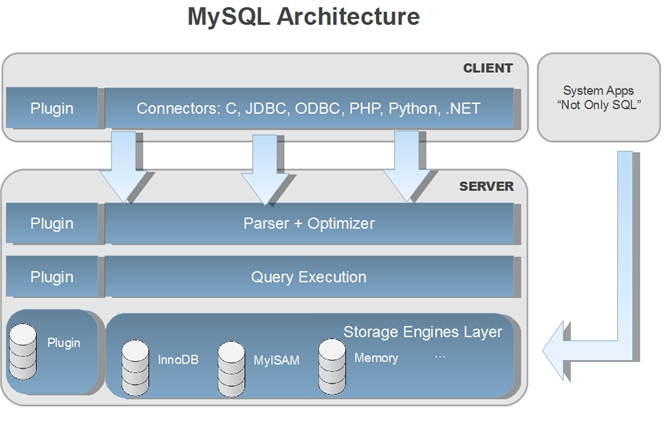 |
Storage layer and engines
In MySQL the storage layer of the database is abstracted. See “Storage engines Layer” in fig. MySQL Architecture. Though the default Storage engine is InnoDB there can be any number of storage engines that can be plugged in at this layer.
InnoDB is an extremely powerful transactional storage engine that has withstood the test of time by handling databases having terabytes of data and used by millions of users.
Since MySQL has an abstract layer and then the real storage engine, the logging is done at 2 levels: first at the abstract storage engine layer and then per storage engine based on the capability of the storage engine. At the abstract storage engine layer the log is called the binary log. At the InnoDB engine level, it can be oversimplified and called the redo log.
The binary log can be used to provide some level of atomicity, consistency and durability between engines but since engines are so varied it is a complex topic and beyond the scope of this article. Later, we will cover another very important feature that uses the binary log for its implementation. Observant readers might wonder about the missing I- Isolation. In a multi-user, multi-threaded database there are thousands maybe millions of transactions that are happening per minute. Isolation is a way to ensure that these transactions are isolated from each other. The database system produces an output as if the transactions are happening serially and not in parallel. There are two high level algorithms that provide isolation, either with locks or via multi-version concurrency control (MVCC). Locking restricts or manages the modification of the same data by multiple transactions. This can lead to a delay in accessing data locked by a long running transaction. MVCC produces a new version of data for each new transaction that is initiated on that data. If any transaction commits, all the other transactions having an older version of the data may need to abort or take the new data into consideration. The InnoDB engine provides Isolation by implementing MVCC.
Besides these fundamentals, the database engine should provide common database features like stored procedures and triggers and a reasonable adherence to the SQL standards.
Development and management tools
Any software is as powerful as the tools that are provided to make the software more usable.
For databases it is important that users can visually model their database using entity relationship (E-R) diagrams to manage the database objects, manage users, and have an easy visual way to modify their existing database. For large installations it is not only important to manage a single instance of the database but also be able to manage multiple database installations. DBA (database administrator) today need to know exactly what is happening with their database in real-time. Is there an installation that is stalled? Is there a user, process or query that is hogging time? An answer to such question in minutes rather than milliseconds may translate to downtime for a database, involving loss of reputation and money. If a large website goes down it is front page news.
However well the data and database is managed, database users need a way to ensure that there is insurance from disaster in the form of a backup of data.
MySQL is shipped with a modern visual tool called MySQL Workbench, which allows users to model and manage their databases as well as their users. For large installations MySQL provides a paid tool called MySQL Enterprise Monitor to manage multiple installations and look at moving graphs of ongoing database activity in the data-center. There are also other tools available from multiple vendors to manipulate and manage MySQL installations. There are multiple free and paid tools available for backing up and restoring a MySQL database.
Some of the tools mentioned above are built on a strong foundation called Performance Schema. Performance Schema is (PS) — a framework that has the meta-data about all that is happening in the database as well as constructs to allow a user to view and filter this data. Performance Schema captures information about users and queries down to threads, mutexes and their corresponding wait times and process times. It contains constructs to allow this fine grained information to be extracted using events and filters. DBAs with a strong knowledge of PS can find out if anything out of the ordinary is happening with their MySQL database. Users can set up the amount of monitoring that they need and the performance schema will populate only the requested data. Since PS is expected to generate a huge amount of data; users can limit the total data stored. The data is transiently stored in cyclic tables in a limited amount of memory.
As computer technology progresses some things change while others remain the same. The number of computer languages available to a programmer is among the things that have changed while the popularity of the old C, C++ and Java remain almost the same. Programmers need to be able to access a database using the language of their choice. The latest enhancements to the database should be made available in the language that they are using. We are fortunate that the hottest new languages want to adopt MySQL. MySQL has excellent drivers for Node.js, Ruby and GoLang. To maintain hundreds of such language connectors is a huge drain on any engineering organization. MySQL is made powerful by the number of computer languages that programmers can use to connect to it. The topmost layer in MySQL Architecture shows the client layer where the connectors exist. Whichever language you may use to write your program, chances are; there will be a connector (or client API) that allows you to connect to MySQL and exchange data with it. The MySQL community is a great source of strength in this area. There are a huge number of language connectors not only written but which continue to be maintained by the MySQL community. MySQL is very lucky to have great community developed drivers for Ruby and GoLang MySQL continues to officially maintain the ODBC, C++, Java, Net and (the most recent) Python connectors.
The community
Any Web product benefits from user and community attention. Attention generates and maintains the cycle of adoption, growth and stability. In the connected socially networked world of today, users expect quick answers to their problems. A large user base also ensures that any problem that a user experiences, may have already been manifested and resolved. Our user community is a huge blessing for MySQL. An open and well informed MySQL user community is ready to answer any questions users may have, related to their MySQL installation. There are a multitude of forums where myriad discussions are recorded about users having difficulties, along with the solutions to those problems. The community generates ideas and sometimes code to improve MySQL, files bugs and most importantly is the sounding board that encourages MySQL developers to do better and compliments them for a job well done.
Redundancy, replication and sharding
As a database grows popular, larger and more highly trafficked websites rely on it. For large and distributed websites, high availability is extremely important. Redundancy needs to be built into all layers of Web architecture, including the database layer. MySQL provides this via MySQL Replication a way to define and manage a series of master-slave set-ups. For some large installations where the read load is much higher that the write load, it makes sense to distribute this read load to many, sometimes hundreds if not thousands; of slave replicas of the master server. MySQL replication has many options to configure these master slave set-ups to ensure that a slave automatically takes over as a master if the master fails. Replication leverages the binary log to ensure that database events are transported from the master to the slave/s database instance. MySQL provides for replication that is row or statement based, synchronous or asynchronous, instant or time delayed. The capabilities are powerful while the administration is easy using tools like Workbench and MySQL Utilities. Database replication is a vast and complex topic with a huge amount of current database research being focused on it. It’s no wonder then that the latest version of MySQL has a number of enhancements for MySQL Replication like check-sums, global transaction ID, crash safe slaves etc.
A different, sometimes complementary, approach to handling large database implementations is to partition or shard the data. A single large table could be broken up into smaller portions depending upon the commonality of the data. For example a user table could have separate partitions or shards based on the nationality of the user. This is especially useful when the most frequent queries require data from a single partition. MySQL has extensive support for table partitioning at the InnoDB storage engine level. The latest labs releases demonstrate how MySQL can be sharded across multiple machines. The entire complexity of identifying the shard on which the required data resides is the responsibility of the new sharding infrastructure called MySQL Fabric.
Security
No real world software is complete without adequate attention to security. A database must ensure that it is secure. In the world of multi-tenancy databases special care needs to be taken to ensure that a user has sufficient privileges before any access is given to the data. MySQL implements user privileges at the database, table and column levels. There are also privileges for objects like views, procedures etc. Besides the normal create, modify and delete privileges, DBAs can also restrict the quantum of a privilege given to a user by, for example limiting the number of queries the user can run per hour or the number of connections the user may open.
MySQL also provides integration with third-party authentication modules like PAM. Recent releases give the MySQL DBA extensive password control to ensure adequate strength of passwords and expiration rules.
Speed
Let us now talk about the speed and efficiency required from a database system for the Web. The easiest way to increase the speed of access to the data is by adding indexes. Indexes should not only be created on simple columns with integers and strings but complex columns with large text fields (called full text or CLOB). The indexation needs to understand the sorting rules for the different world languages and character sets. Users with large databases need the option to create sub-indexes or secondary indexes on the primary index. Indexes should be quick to create and quick to update when new data is added. MySQL provides easy index creation and modification with some special techniques for fast index creation. The latest version of MySQL provides options to create a full-text index for all language collations. On the fly creation and deletion of indexes is also offered by the latest version of MySQL.
The speed of a query depends on the amount of data that needs to be fetched for a query, for complex queries the sequence of fetching the data may matter. The optimizer uses statistics about the data contained in the database to determine the most efficient sequence for fetching data. Optimizers are complex and constantly changing because of the complex filtering, increasing the size and wider distribution of data that needs to be gathered for the query. MySQL database’s speed is also enhanced by its versatile optimizer. MySQL is constantly working on our optimizer which continues to evolve. The latest version of the optimizer provides exponential speed improvements for several classes of queries.
When databases were first created hard disks were in vogue, and many database algorithms were based on the rotation and buffering attributes of hard disks. Databases today need to adapt to the new world of solid state devices (SSDs). Though these devices are currently expensive, a limited use of these can result in huge speed gains. Databases for the web need to be SSD aware. The newest MySQL is adapting to use SSDs. It is now possible to relocate portions of the database which are more frequently accessed to a different path. A user can now choose his log files to be on a path which points to an SSD. The same flexibility is also provided for portions (read partitions) or complete tables or table spaces.
On the hardware side, there is not only progress in terms of SSD’s but the nature of the microprocessor itself has changed. The microprocessor technology continues to increase the number of processors on the chip and multiple cores on each processor. This means that a server has multiple threads and these threads can run uninterrupted on their separate core. This has huge implications for finely tuned software like a database servers. The thread bottlenecks and points of contention are now very different from a single or dual core chips. The database therefore needs to be re-architected to take advantage of say 64 threads running at the same time. Users expect that if they spend money to upgrade from a 32 core machine to a 64 core machine, the throughput of the database should also double. The MySQL team has had to work hard on architecture to ensure that the latest MySQL scales almost linearly up to 64 cores and half a million queries per second.
Read DimitryK’s blog at http://dimitrik.free.fr/blog/index.html for benchmark numbers for MySQL
(Figure 2).
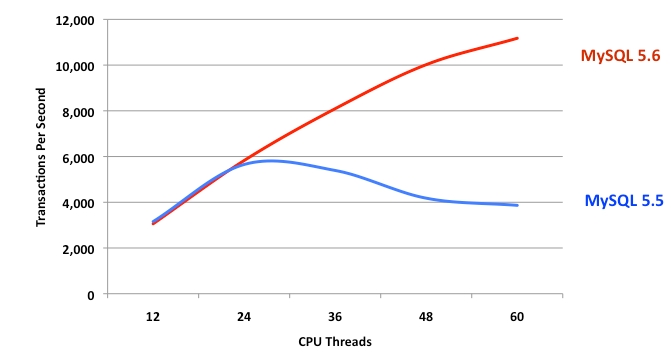 |
Flexibility—online schema changes
Since I already talked about scalability earlier, let me devote the final paragraphs to flexibility
The current trend of NoSQL was initiated because database users felt constrained at having to define a fixed schema before developing their application. With today’s agile models; schema changes happen more frequently and need to happen dynamically on 24×7 sites. These sites are business critical and down-times for these changes are very expensive for an Internet business. Paradoxically, increasing competition means that new changes need to be provided at the speed of the Internet, without disruption to the current production environment. Traditionally, changing database schemas was a huge investment of time for a database that did not allow dynamic schema changes. This business requirement has led to the new online schema change model which the latest MySQL 5.6 also supports. You can add and modify columns in a table on the fly. New indexes can also be created and dropped online. Relationships between tables in the form of foreign keys can also be altered while the server is running.
This is the Internet age and trends rise and get established very quickly. One of the ways for any software to provide flexibility to its users is to embrace upcoming trends. MySQL adapted to the NoSQL trend by providing their users an option to access data using either SQL or NoSQL.
The user gets the full advantage of having a strong ACID compliant underlying layer while having the flexibility of a schema-less data architecture. The protocol we have chosen to expose for NoSQL is the memcached protocol. So if you have a running application using memcached you can choose to use it with MySQL. Since the NoSQL interface connects to the lowest layer of MySQL (See MySQL Architecture), there is no SQL processing overhead from the parser/optimizer and query execution layer.
MySQL has also embraced the big data trend with the integration of Hadoop using the MySQL applier for Hadoop. This allows realtime transfer of data from MySQL to a Hadoop database. Big data is being used to crunch the huge data coming getting created on the web. This data is being generated from multiple sources including devices connected to the Web. And since the underlying database of the web is MySQL, it is important that Hadoop and MySQL talk to each other realtime.
There are multiple success stories of MySQL which you can read on the web. Would encourage you to read blogs from Twitter (new-tweets-per-second-record-and-how), Facebook (Mark Callaghan).
Staying at the forefront and remaining the most popular database is a complex and interesting challenge for the MySQL development team. We thank you dear reader for your support and attention.
Latest Posts
-
NoSQL + SQL = MySQL 8; Keynote OSI2019
NoSQL + SQL = Mysql 8 Open Source India 2019 keynote from Sanjay Manwani Slides from the keynote presented at Open Source India 2019 at…
-
MySQL 8 loves Javascript @jsfoo
Presented at the JSFoo conference for the first time. The slides are uploaded here https://www.slideshare.net/SanjayManwani/mysql-8-loves-javascript via @SlideShare Quick impression on the conference: 1. Very buzzy…
-
MySQL Whats New #gids16; slides
Had a wonderful session at the Great Indian Developer Summit 2016. Thanks Saltmarch for a Great conference with wonderful attendance. Lots of interest in MySQL…
-
MEB 4.0 allowing backup of MySQL 5.7 is GA
MEB 4.0. ensures that the MySQL Server 5.7 enhancements like the new 32 and 64 K page sizes and general table spaces can also be…
